Chapter 13 Morphology, Grammar, and the Lexicon
- Note:
- An earlier version of some of these analyses was first reported in Braginsky et al. (2015).
How does abstract structure emerge during language learning? On some accounts, children’s early syntax emerges from direct generalizations from particular lexical items, while on others, syntactic structure is acquired independently and follows its own timetable. CDI data can help us decide between these two views. In this chapter, we summarize the state of grammatical development across languages (noting the challenges posed by radically different representations of grammar across CDI forms). We also replicate and generalize analyses linking grammatical generalization to children’s vocabulary size (see Chapter 15 for links to vocabulary composition as well). We end by pursuing two relatively more novel directions. First, we investigate the idea that that age modulates the relationship between grammar and the lexicon. Second, we use structural equation modeling to evaluate the directionality of this relationship.
13.1 Introduction
For many children, their first words are spoken in isolation. While these single word utterances sometimes seem to be picking out objects in the world (e.g., ball!), others seem to convey more complex ideas or desires (e.g., up! for Mommy, pick me up!). By two years of age, however, many children have acquired a large repertoire of words, and are beginning to use them in two- or three-word combinations (e.g., Mommy up! or kitty sleep here). These utterances will gradually increase in length and complexity in various ways, forming sentences that increasingly reflect the grammatical structure of their native language (e.g., Mommy, the kitty is sleeping here). Children also begin to add more verbs, adjectives, and other predicates to their working vocabularies (see Chapter 11), and substantively increase their use of prepositions, articles, and other closed class forms that do grammatical work, including the productive use of inflectional morphemes (e.g., English past tense -ed or -ing).
Understanding the origins of grammar is critical because children’s ability to use morphosyntactically-rich language is thought to reflect the uniquely-human mental machinery that enables speakers to comprehend and produce novel utterances that have never been heard in the input (Berko 1958; Pinker 1991). The questions surrounding the development of grammar are challenging. How do abstract morphosyntactic structures emerge during language learning? What mechanisms underlie the formation of generalizations that support such inferences and allow children to apply them during language production? Does an understanding of the abstract rule-structure of language emerge from the interactions of individual words, or is that structure acquired independently and represented separately?
Broadly speaking, theoretical views on grammatical development generally take one of two forms. On nativist theories like Principles and Parameters (Chomsky 1981; Baker 2005), grammar emerges independently from lexical knowledge following its own, largely maturational, timetable. Moreover, grammatical regularities are mentally represented in a format that is distinct from that used by the lexical system. In contrast, according to lexicalist theories, mental representations of morphosyntactic structure generally emerge from partial, probabilistic generalizations that are extracted over exposure to lexical items, and at least early in development, there may be little or no representation of morphosyntactic rules or regularities per se (Tomasello 2003; Elman et al. 1996). Even when syntactic structures are eventually represented, these representations are directly related to more concrete lexical structures (Bannard, Lieven, and Tomasello 2009).
Historically, the study of individual differences has been critical to this debate. While variation in word learning is generally uncontroversial, individual differences in grammatical development do not illuminate core processes of acquisition under a universalist, nativist perspective. In contrast, lexicalist theories predict that variation in grammatical development is significant, in that such variation should be tightly yoked to variation in lexical development (Bates and Goodman 1999). Research has shown that, as with lexical development, there is sizable variation in exactly when and how children move into using more grammatically complex utterances in their everyday speech. While some children use primarily multi-word phrases and many closed class forms by 24 months, other children are still primarily producing nouns in single word utterances at that same age (e.g., Bates, Bretherton, and Snyder 1988; Bates and Goodman 1999). Moreover, there is also variation in the kinds of multi-word utterances that children produce. For example, some children build up sentences from individual words (e.g., want dat!), whereas other children seem to produce utterances that reflect “unanalyzed” chunks of more complex speech (e.g., iwantdodat!).
13.1.1 Correlations between grammar and the lexicon
Associations between individual differences in lexical and grammatical development have been robustly substantiated in the literature. In the original norming data from the English CDI Words & Sentences, children with more sophisticated grammatical productions were also those children with the largest vocabularies (Bates et al. 1994). Using that same dataset, Marchman and Bates (1994) found that size of verb vocabulary was concurrently related to children’s overregularization of past tense inflections (e.g., daddy goed), productions that are viewed as a major milestone in the development of grammatical rule-based knowledge.
Links between lexical development and grammar have also been reported longitudinally (Bates, Bretherton, and Snyder 1988; Bates and Goodman 1997), in late talkers (e.g., Paul 1996; Rescorla, Dahlsgaard, and Roberts 2000; Rescorla, Roberts, and Dahlsgaard 1997; Thal et al. 1997), early talkers (Thal et al. 1996, 1997), Spanish-English bilinguals (Marchman, Martı́nez-Sussmann, and Dale 2004), and children with neurodevelopmental disorders, such as Williams syndrome (e.g., Singer Harris et al. 1997). Similar relationships have also been demonstrated in many other languages, including Slovenian (Marjanovič-Umek, Fekonja-Peklaj, and Podlesek 2013), Hebrew (Maital et al. 2000), Icelandic (Thordardottir, Weismer, and Evans 2002), Italian (Caselli, Casadio, and Bates 1999; Devescovi et al. 2005), Bulgarian (Andonova 2015), Finnish (Stolt et al. 2009), Spanish (Mariscal and Gallego 2012; Thal, Jackson-Maldonado, and Acosta 2000), and German (Szagun et al. 2006). Thus, these findings should be considered among the most reliable in the literature on CDI analyses.
Finally, and perhaps most intriguingly, in behavior genetic studies of monozygotic and dizygotic twins, the relation between lexical and grammatical level has been found to be strongly heritable (Dale et al. 2000; Dionne et al. 2003). In other words, even though genetic factors contribute relatively modestly to each aspect of language as assessed individually, the genetic factors that influence lexical growth are the same as those that influence grammatical growth, perhaps operating in a bidirectional manner.
While these studies are consistent with the view that vocabulary and grammar development are strongly associated developmentally, the interpretation of these relations is still under debate. Some researchers have interpreted these links to suggest that domain-general learning mechanisms guide the child’s construction of a working linguistic system at many different levels, in this case, learning words and learning grammatical rules (e.g., Elman et al. 1996). As Bates and MacWhinney (1987) proposed many years ago, “the native speaker learns to map phrasal configurations onto propositions, using the same learning principles and representational mechanisms needed to map single words onto their meanings” (p. 163).
In contrast, other proposals suggest that the process of learning words involves learning both their lexical-semantic and their morphosyntactic properties (e.g., in what constructions they can legally appear and what inflectional morphemes are required), and that grammatical knowledge is generally built up on a case-by-case basis (Tomasello 2003). Early word combinations are often highly routinized and situation specific, suggesting that learning grammar, like word learning, is guided by learning mechanisms that are item specific and frequency dependent. It is only later that grammatical structures become encoded in terms of their abstract syntactic form (e.g., Lieven, Pine, and Baldwin 1997; Tomasello 2003). And yet other accounts view the relation as reflecting mechanisms that operate in the opposite direction. On these views, grammatical analysis is a driving force behind word learning, such that the process of analyzing sentences into their constituent grammatical parts facilitates the further acquisition of lexical-semantic knowledge (Anisfeld et al. 1998; Naigles 1990).
Recently, a literature has developed using longitudinal models to assess the directionality of these relations. Such studies use cross-lagged models to investigate whether vocabulary size at earlier time-points predicts grammar at later times and vice versa. These models provide a perspective on growth over time that can help describe the directionality of the relationship, even though they do not allow for causal inferences about that directionality (Rogosa 1980). Unfortunately, studies using such methods have come to very different conclusions, perhaps owing to the different models and datasets they have used. In one study, Pérez-Leroux, Castilla-Earls, and Brunner (2012) found relations from vocabulary size to grammar in 3–5 year-old Spanish speakers. In contrast, Brinchmann, Braeken, and Lyster (2018) found relations in the opposite direction, with stronger paths from grammar to vocabulary in a sample of 4–6 year-old Norwegian children. And using data from Spanish-English bilingual 2.5–4 year-olds, Hoff, Quinn, and Giguere (2017) found limited evidence for direct relationships between growth in grammar and vocabulary, and proposed that the observed relations were actually the result of third-variable explanations, perhaps from common input to both systems (Hoff, Quinn, and Giguere 2017). Thus, the evidence at present is complex and unresolved.
13.1.2 The current analyses
In this chapter, we explore relations between estimates of children’s vocabulary size based on the vocabulary checklist and responses on other sections of the Words & Sentences instruments. Many versions of the instruments provide indices of grammar learning by asking about children’s use of inflected forms (e.g., walked) and overgeneralizations (e.g., goed), as well as the complexity of their multi-word combinations (e.g., kitty sleeping / kitty is sleeping). While many studies have examined associations between lexical and grammatical development cross-linguistically, the scope and power of these early studies were limited, with few opportunities for direct comparisons of the nature or extent of these relations across multiple languages at the same time. In contrast, our data allow analyses of lexical-grammar relations with enhanced statistical power and broader cross-linguistic representation.
In addition, we explore a hypothesis that has not been explicitly tested in these earlier studies: that there remains age-related variance in grammatical development unexplained by vocabulary development. While the overall relationship between grammar and the lexicon provides support for lexicalist theories, the identification of age-related variance would suggest the presence of developmental processes that regulate grammar learning, above and beyond those captured by measures of vocabulary size. Such age-related processes could be either maturational or experiential, and either domain-general (like working memory) or language-specific (like grammatical knowledge). Importantly, since both nativist and constructivist theories could in principle predict age-linked variance in grammatical development, our goal is not to differentiate these theories, but instead to test this novel prediction and explore its implications for future work on understanding the processes of grammatical development.
Further, addressing the question of directionality in the relationship between grammar and the lexicon, we fit structural equation models to longitudinal data from two datasets. We use a variant on the standard autoregressive cross-lag panel model that accounts for stable trait differences between individuals (Hamaker, Kuiper, and Grasman 2015). While such models do not provide conclusive evidence about the nature of developmental links between grammar and the lexicon (cf. Rogosa 1980), they nevertheless provide suggestive evidence that – at least for young children – vocabulary drives grammatical growth, rather than vice versa.
A final contribution of our work is that, due to the size of our dataset, we are able to make more fine-grained distinctions than the initial cut between grammar and the lexicon. In particular, we distinguish morphology from multi-word syntax, since morphological generalizations might be more specifically dependent on vocabulary size than those requiring more global, sentence-level syntactic regularities.
13.2 Methods
CDI forms typically contain both vocabulary checklists and other questions relevant to the child’s linguistic development. All of the data reported here come from Words & Sentences type forms, administered to children ages 12–36 months (most in the 16–30 month range). In addition to the vocabulary checklist items, these forms typically contain a single item asking whether the child is combining words at all. There is also a Word Form section, which asks whether the child produces each of around 30 morphologically inflected forms of nouns and verbs (e.g., feet, ran); and a Complexity section, which asks whether the child’s speech is most similar to the syntactically simpler or more complex versions of around 40 sentences (e.g., two foot vs. two feet, there a kitty vs. there’s a kitty).
Importantly, each instrument for languages other than English is not just a translation of the English form, but rather was constructed and normed to reflect the nature and early development of the lexicon and grammar of that language. Thus, there are substantial differences in the content of these items and their coverage of different morphological and grammatical phenomena. The major commonality is that the form developers have attempted to provide a comprehensive and representative survey of important developmental phenomena in their language.
Even more so than many parts of the CDI, responses to individual word form and grammatical complexity items should be interpreted with caution. Such items have not been validated as extensively as other parts of the CDI.24 In addition, children’s early speech is thought to be inconsistent from a grammatical perspective, occasionally alternating word orders beyond the standard word order of the language (e.g., Bowerman 1973). This last point goes double for word forms, which are often highly variable within individuals (Marcus et al. 1992). Finally, word forms like “went” may be used by the child appropriately to denote motion without understanding the temporal marking that distinguishes it from the less-frequent “go.”
Keeping these caveats in mind, to analyze lexical and morphosyntactic development, we derive several measures. Each child’s vocabulary size is computed as the proportion of words on the corresponding CDI form that the child is reported to produce. Similarly, each child’s Word Form score is the proportion of word forms they are reported to produce, and their Complexity score the proportion of complexity items for which they are reported to use the more complex form. We compute all of these quantities as proportions to make the scales comparable across languages. Note that different analyses often incorporate different amounts of data due to the presence or absence of specific sections (or data from those sections) in particular language datasets.
13.3 Results
We present four sets of results. First, we show analyses of the “combines” item, which is a binary item in which parents indicate whether their child is combining words. Second, we analyze the relations between vocabulary size and the Word Form and Complexity items. Third, we follow up on a pattern reflected in the “combining” item, namely age-related modulation of the grammar-lexicon relationship. Finally, we investigate the degree to which the age-related pattern is found in individual items.
13.3.1 Combines
Figure 13.1 shows the probability of a parent checking that their child combines words, plotted by the child’s chronological age (left) and raw productive vocabulary size (right). As can be seen, across 7 languages, there is some consistency in the developmental trajectories for this item. By 19 months, around 50% of children are reported to be combining words; by 25 months, around 90% are combining.
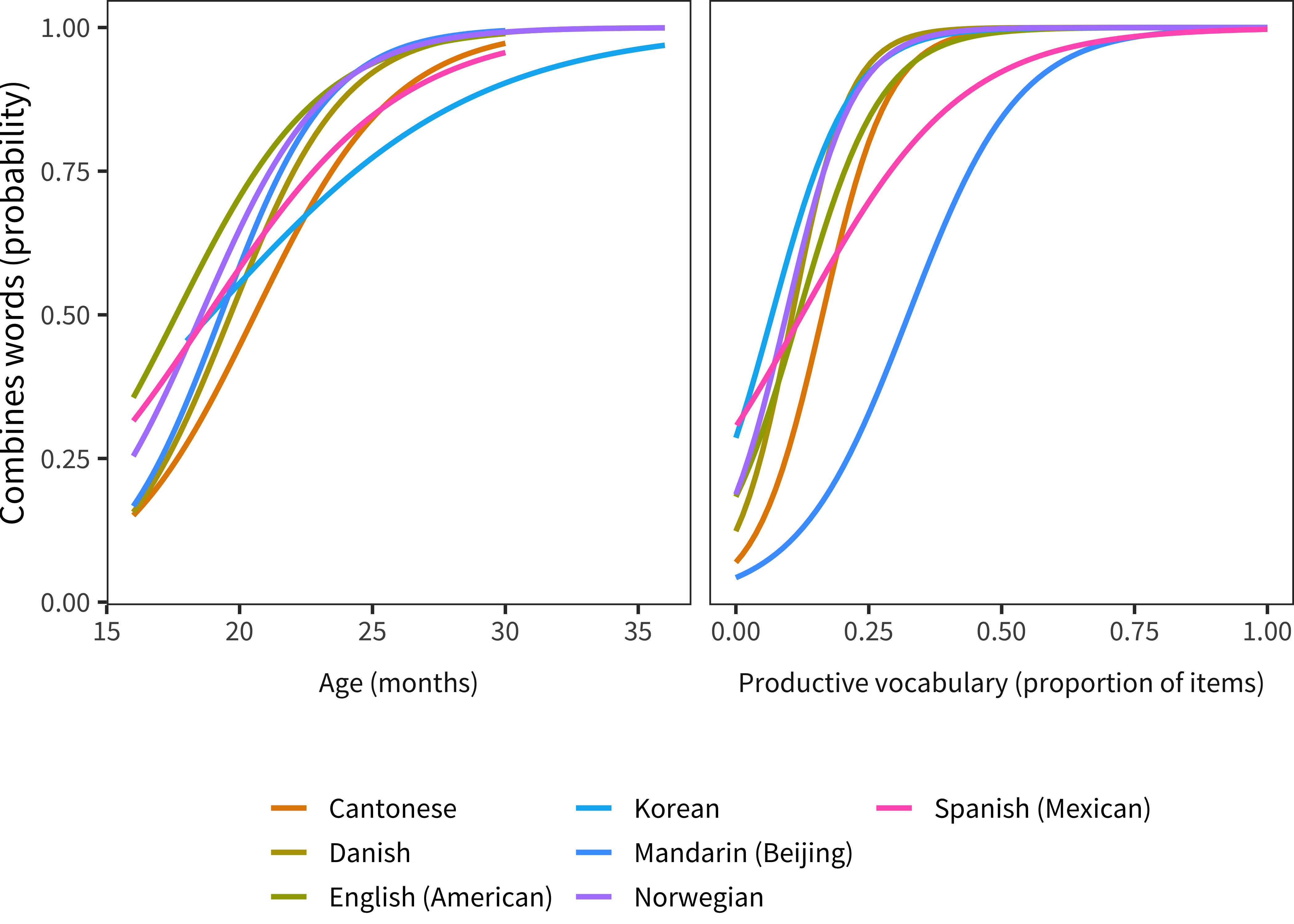
Figure 13.1: Trajectory of the Combines item in each language across age (left) and vocabulary size (right).
Vocabulary-related trajectories are more variable, however. In general, children who were marked as combining had vocabularies larger than around 100 words. There are several notable exceptions, however. As noted in Chapter 5, raw Beijing Mandarin vocabulary in the WS form is unusually high, but the “combines” item does not appear to be comparably accelerated. Thus, Beijing Mandarin-learning children appear to be combining words only after producing substantially more words than children learning other languages. On the opposite side, children learning Québécois French and Korean were reported to be combining with quite small vocabularies.25
To investigate the quantitative relationship between word combination (as measured with this item), age, and vocabulary, we fit a logistic mixed effects model predicting whether a child combines as a function of their vocabulary (as proportion of items), age, and interaction between vocabulary and age. We also included a random effect of language, with a random intercept and random slopes for vocabulary and for age. Coefficient estimates from this model are shown in Figure 13.2.
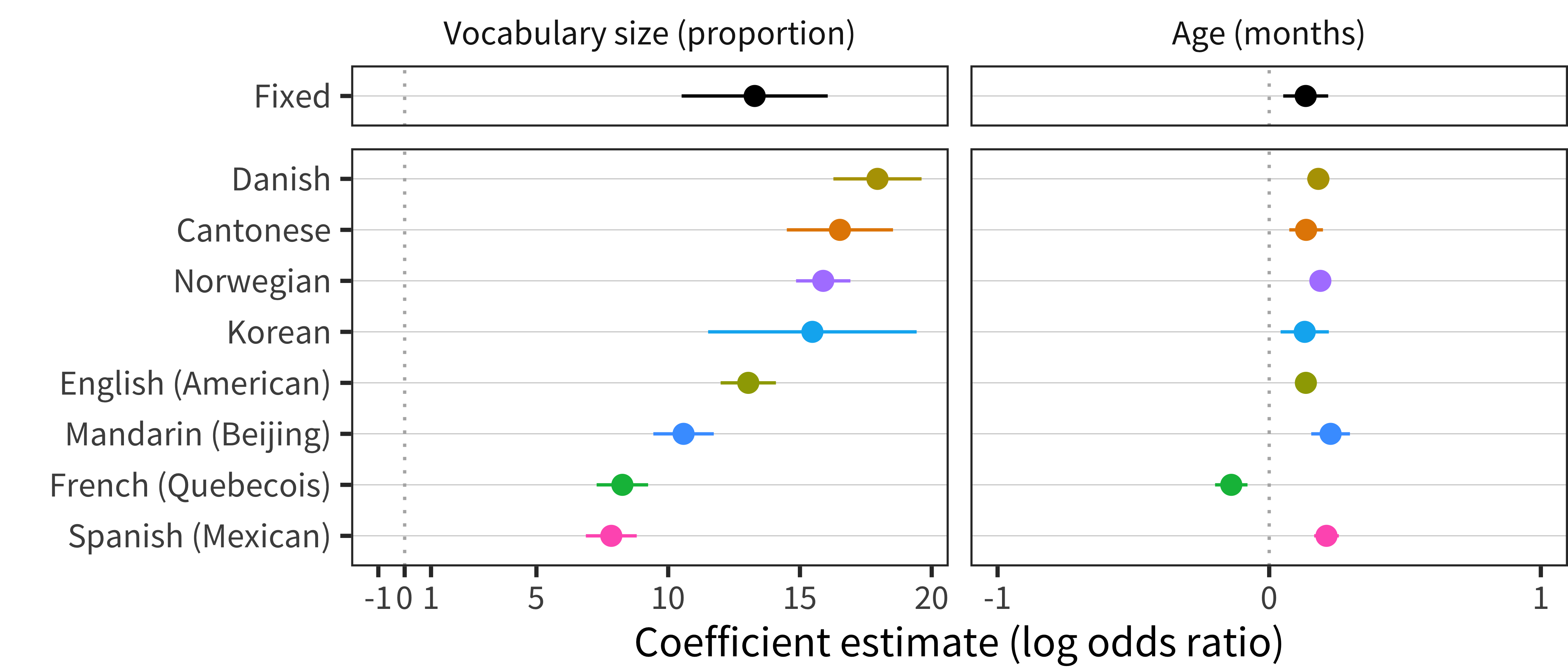
Figure 13.2: Coeffient estimates from Combines model, with fixed effects in the top row and random effects in the bottom row.
This model shows a large effect of vocabulary (\(\beta\) = 13.28, t = 9.39), with a relatively smaller effect of age (\(\beta\) = 0.13, t = 3.18). These effects mean that, for example, a 16-month-old learning American English with a vocabulary size of 50 words has a 31% chance of combining words. At the same age of 16 months, a child is more likely to combine by about a factor of 2 if she has a vocabulary size of 120 words (at 63%). Conversely, at the same vocabulary size of 50 words, a child is more likely to combine by about a factor of 2 if she is 28 months old (at 63%). In addition, there is a substantial negative interaction of vocabulary and age (\(\beta\) = –0.34, t = –6.94), indicating that older children are more likely to be combining words, even with smaller vocabularies. This result parallels others reported below suggesting that there are age-related components in grammatical performance, at least for production of word combinations, that are unaccounted for by vocabulary alone.
13.3.2 Grammar and Lexicon Relationship
We next examine the correlation between the proportion of Word Form items and Complexity items completed and the proportion of vocabulary items completed. First reported by Bates et al. (1994), these correlations are extremely robust, and can be observed in all of our datasets. Figure 13.3 shows this relation for Word Form items. We fit generalized linear regressions predicting Word Form score or Complexity score as a function of linear, quadratic, cubic, and quartic terms of productive vocabulary size (subtracting the intercept to ensure that the function passed through the origin, because a vocabulary size of 0 necessarily implies scores of 0). The total r² for these relationships ranges from 0.82 to 0.93.
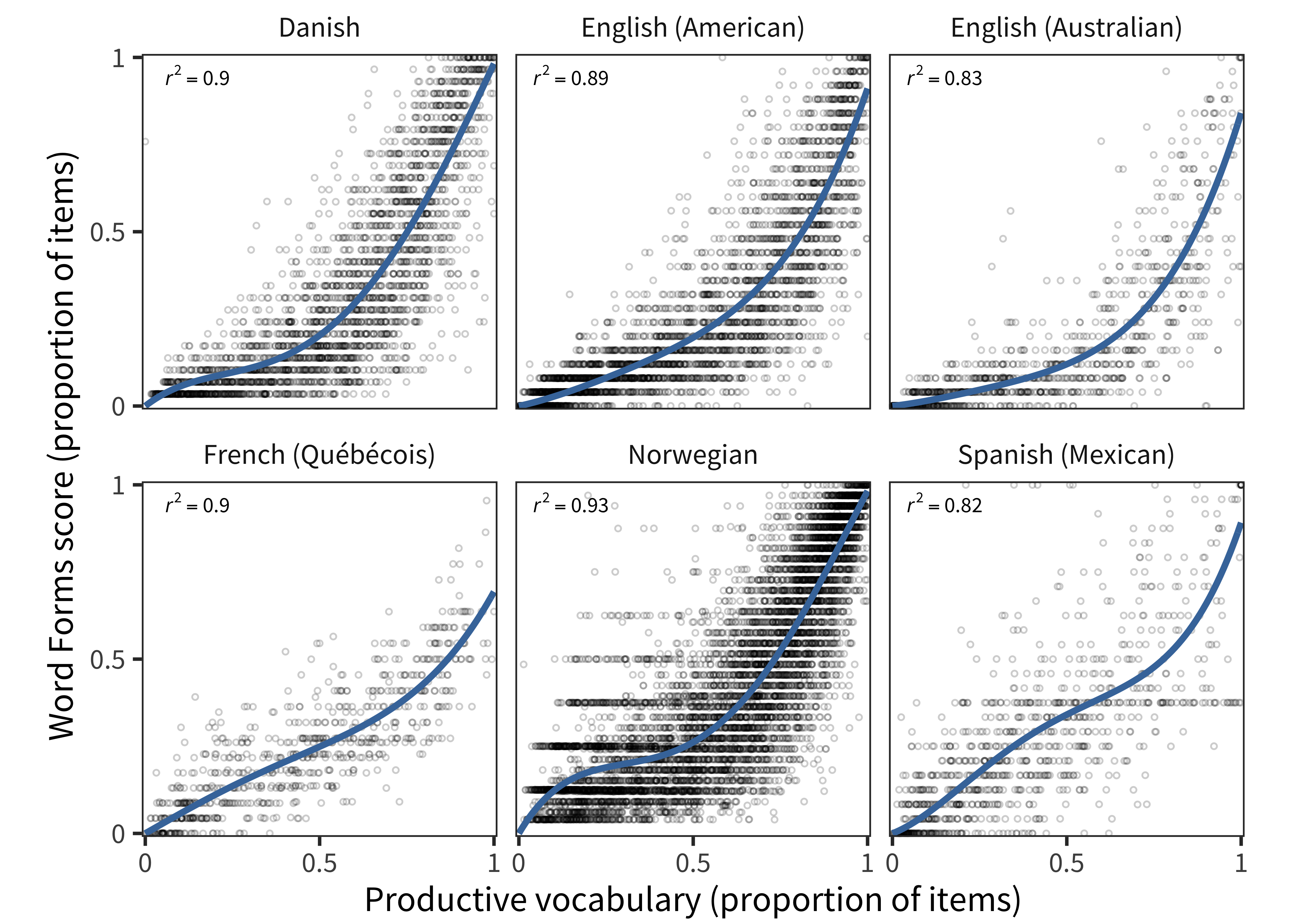
Figure 13.3: Each child’s Word Forms score as a function of their vocabulary size in each language (curves show model fits).
Complexity items show the same relationship (Figure 13.4), typically with equal or greater strength (depending on data density and number of items). r² values vary from 0.75 to 0.94. Some ceiling effects are observed.
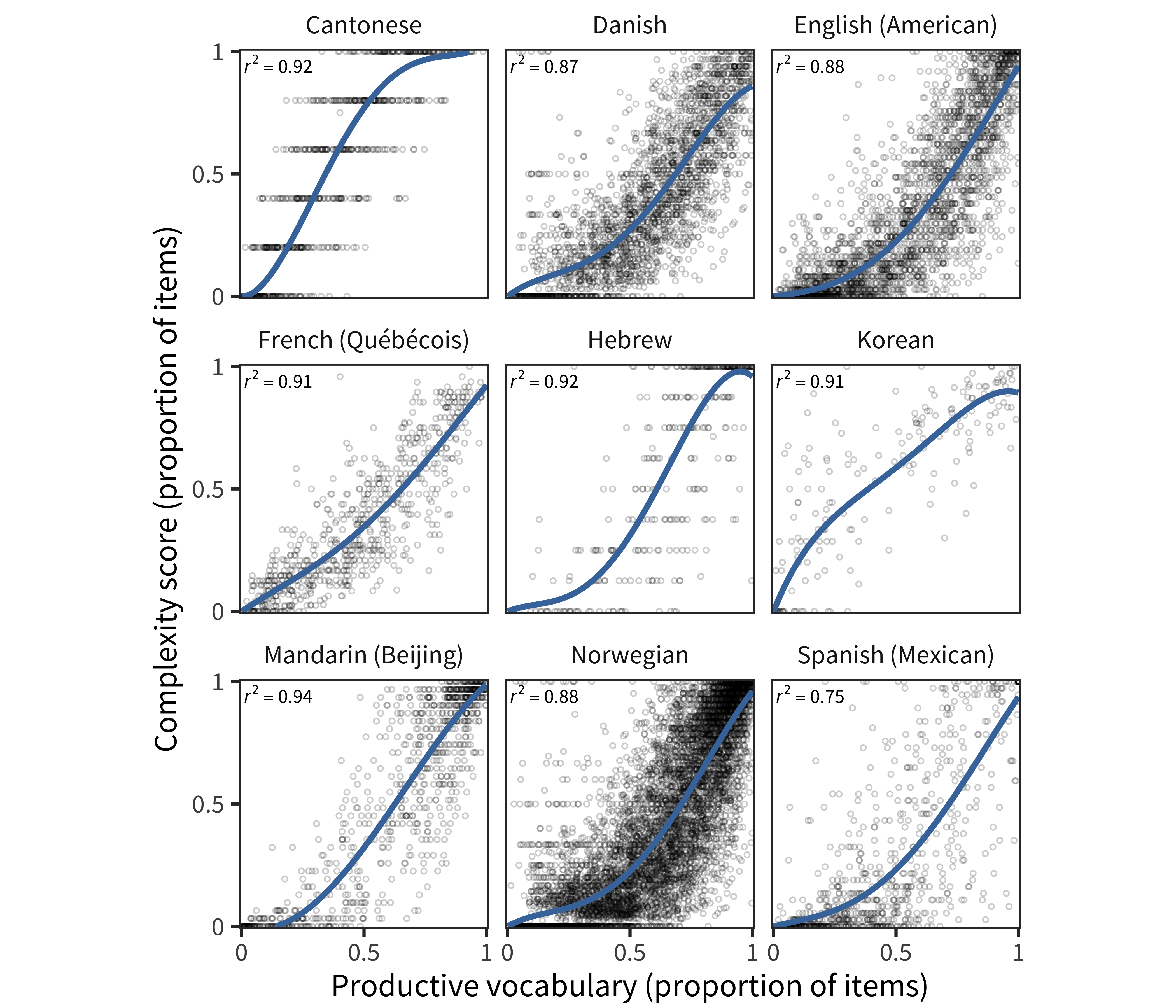
Figure 13.4: Each child’s Complexity score as a function of their vocabulary size in each language (curves show model fits).
Overall, these data add strong cross-linguistic support to the claim of Bates et al. (1994) and others that the emergence of grammatical competence in production is related across individuals to the size of the productive vocabulary.
13.3.3 Age effects
In our next analysis, we follow up on the relationship between age and grammatical ability found in the “combines” analysis above. In that analysis, we noted that less vocabulary was needed for older children to be marked as combining words, suggesting that other abilities can contribute or supplement vocabulary in achieving this milestone. We investigate this pattern in the full Word Form and Complexity item set by splitting data from each language by age. We plot the same curves as above, but separately for children older and younger than the median age (within each dataset).
In essentially every language, for both Word Form (Figure 13.5) and Complexity items (Figure 13.6), we see a higher curve for older children than younger children. This finding is consistent with the idea that grammatical development is faster per unit lexicon for older children (mirroring the negative interaction shown for the “combines” item). That is, an older child with comparable vocabulary to a younger one will likely be better at combining words.
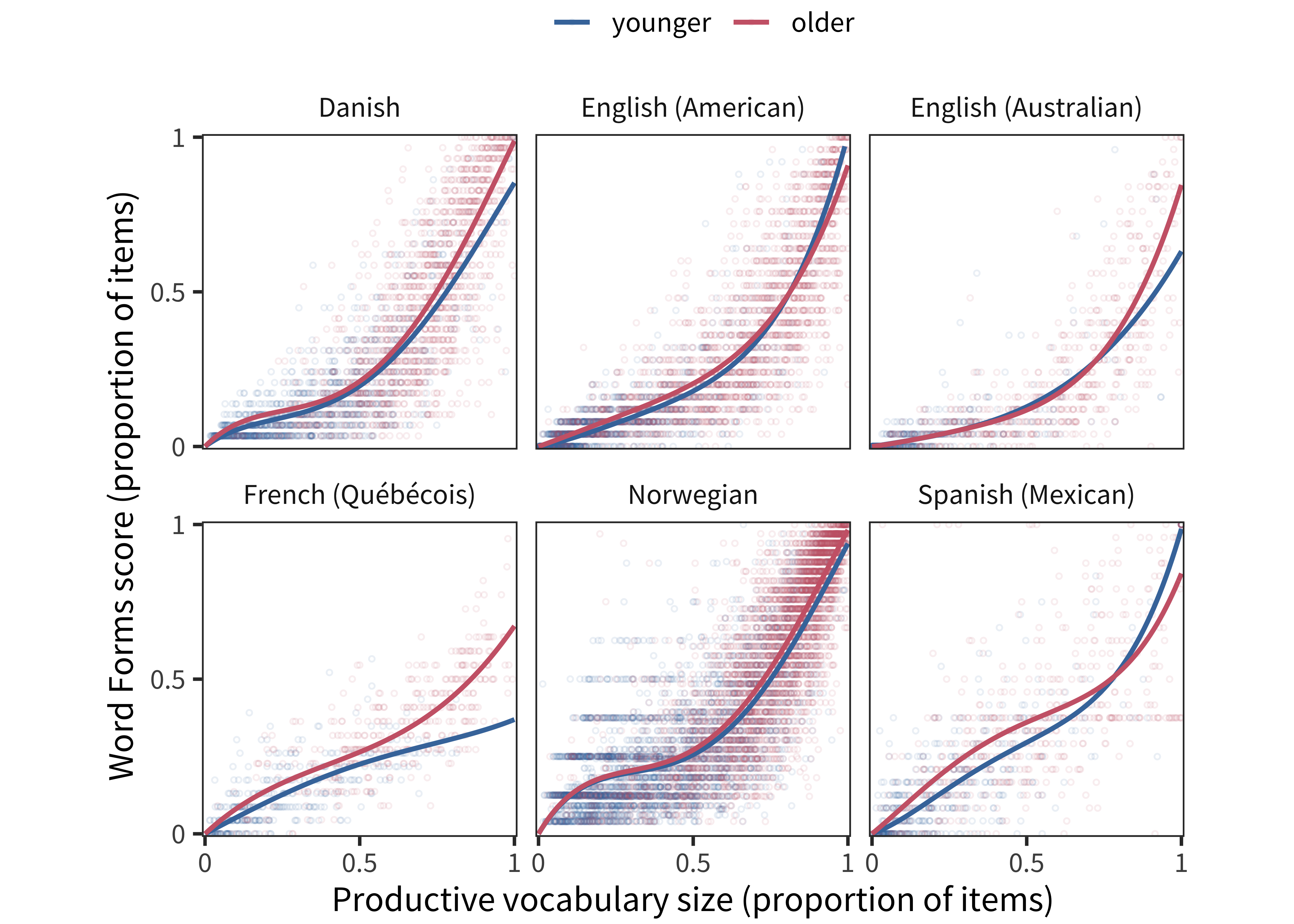
Figure 13.5: Each child’s Word Forms score as a function of their vocabulary size in each language for children younger and older than the median (curves show model fits).
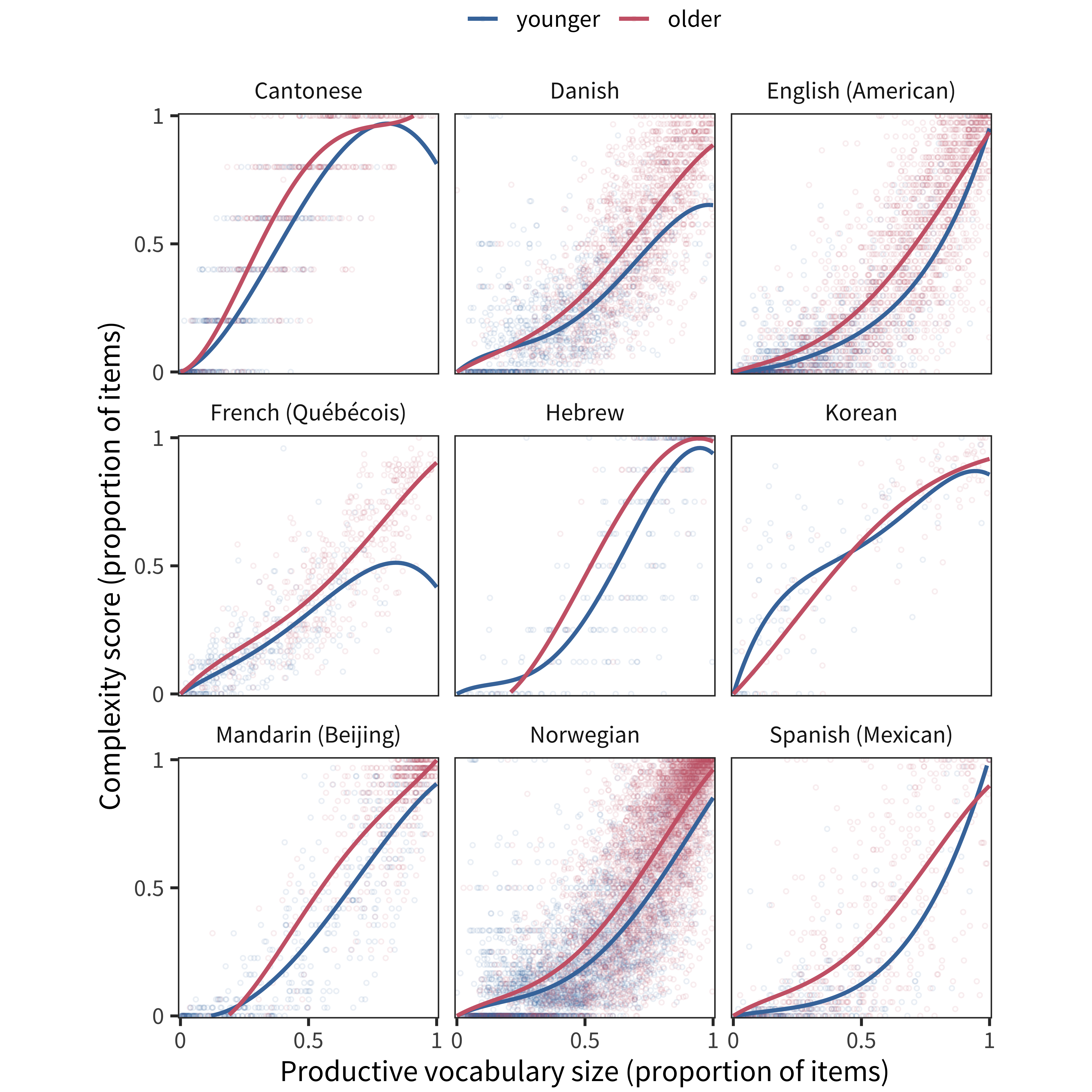
Figure 13.6: Each child’s Complexity score as a function of their vocabulary size in each language for children younger and older than the median (curves show model fits).
This pattern is further summarized in Figure 13.7, where we show the area under the grammar/lexicon curve for younger and older children. The upward slope from younger to older of nearly every line demonstrates the consistency of the age effect, which we discuss further below. In addition, there is a trend for age effects to be larger in Complexity items compared to Word Forms, suggesting that factors beyond vocabulary size have a larger effect on syntax than on morphology.
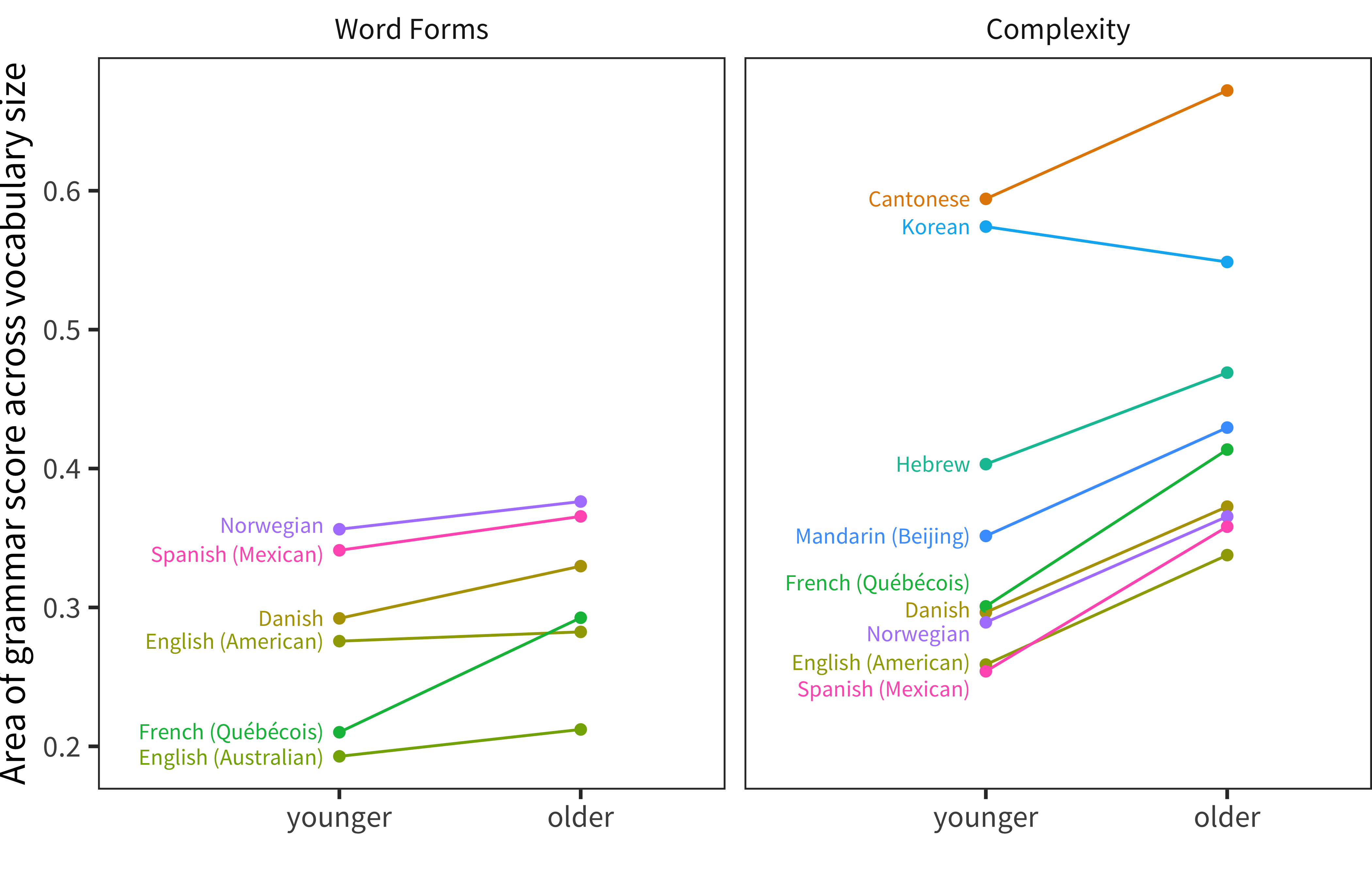
Figure 13.7: Area under model fit curve for Word Forms score and Complexity score as a function of vocabulary size in each language for younger and older children.
13.3.4 Individual items
In our next analysis, we examine the individual items on the Word Form and Complexity sections. Given the heterogeneous nature of the CDI instruments, particularly in the Complexity sections, we attempted a more fine-grained item-analysis by classifying items as capturing either more morphological or more syntactic phenomena. Items for which the difference between the simple and complex sentences is in the inflection of a noun or verb (such as kitty go away / kitty went away) were coded as Morphological. Items were coded as Syntactic if they involved the use of some sentence-level syntactic construction (such as you fix it / can you fix it). Some languages’ items involved a mix of the two or otherwise didn’t fit into this dichotomy, in which case they were coded as Other.
We then a fit logistic regression separately for every item, predicting whether children produced the item from vocabulary size and age. Figure 13.8 shows the resulting model fits for two example items. For both items, children with larger vocabulary sizes are more likely to produce it than children with smaller vocabulary sizes (the curves have positive slopes), and older children are more to produce it than younger children (the older curves are higher than the younger curves). For the item on the left, the interaction between vocabulary size and age is very small (all the curves have roughly the same slope), while for the item on the right this interaction is large (the older curve is much steeper than the younger curve, indicating that at larger vocabulary sizes the advantage for older children is larger).
Figure 13.9 shows for each item, the coefficients of vocabulary size, age, and their interaction. In general, age effects are smallest for Word Form items, larger for Morphological Complexity items, and largest for Syntactic Complexity items, suggesting that more syntactic phenomena likely have greater age contributions.
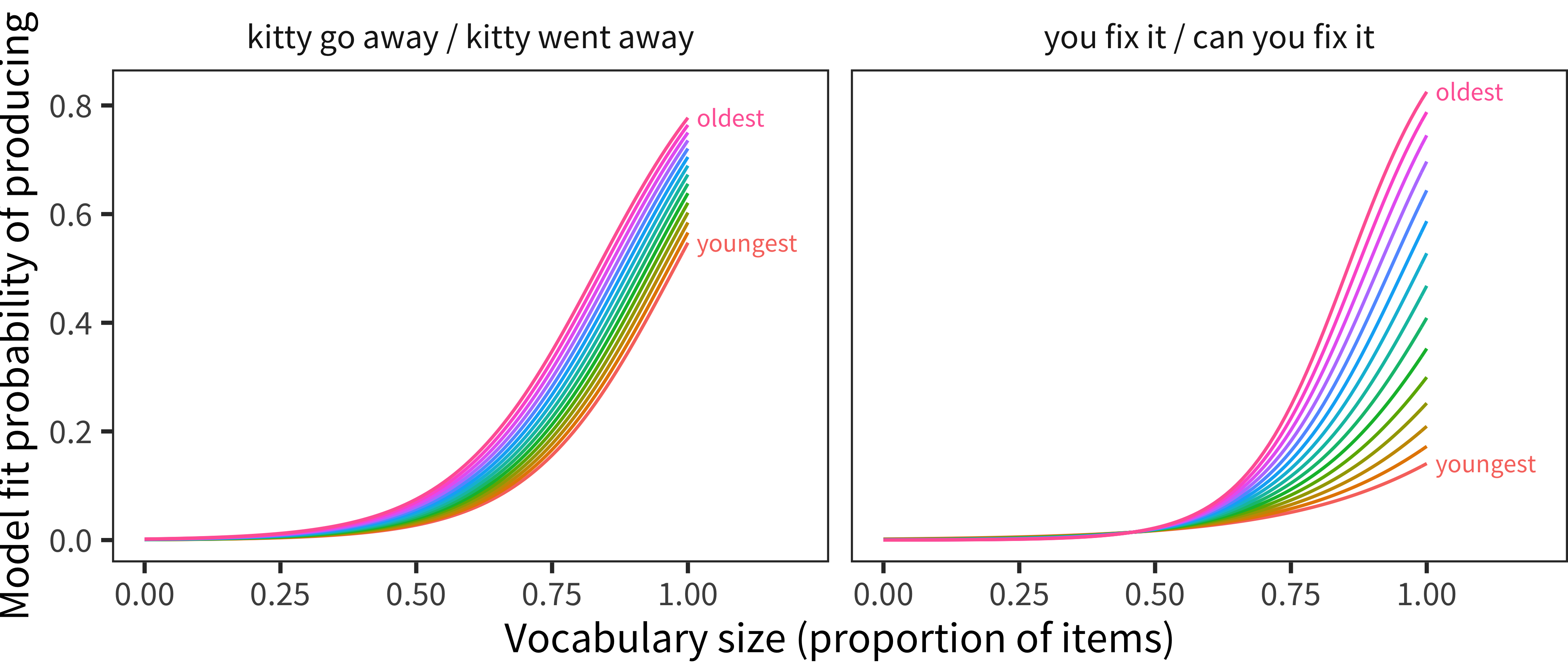
Figure 13.8: Model fits for two example items.
Figure 13.9: Coefficient estimates (as log odds ratio) for each grammar item in each language. Line segments indicate means effect for category.
Building on previous analyses that showed a strong relationship between lexical and grammatical development, we added age into this relationship. Across languages, our measures of syntactic development consistently showed greater age modulation than measures of morphological development. Further distinguishing between items that were more reflective of morphology than syntax, we again found greater age effects for more syntactic items. Thus, this analysis provides evidence for a relationship between syntactic development and age that is not captured by lexical development.
13.4 Longitudinal relationships
In our next set of analyses, we take advantage of the presence of longitudinal data in two languages (Norwegian and American English) to investigate the relationship between vocabulary size and grammatical ability, as operationalized by average Complexity score. As mentioned above, this relationship has been the subject of a variety of previous investigations using longitudinal data (Dionne et al. 2003; Moyle et al. 2007; Pérez-Leroux, Castilla-Earls, and Brunner 2012; Hoff, Quinn, and Giguere 2017; Brinchmann, Braeken, and Lyster 2018), but outcomes have been contradictory. Given the heterogeneity of these studies, results could differ for a variety of reasons, including the language background of the participants, the target age range of the study (which ranged from 2–6 years old), and the nature of the specific models being fit to the data.
Further, a specific technical concern underlies one potential source of variance. The standard method for examining reciprocal relationships between longitudinally-measured variables is the cross-lagged panel model (CLPM). While this model does not allow for causal inferences (Rogosa 1980), it is a convenient way to estimate temporal precedence in the relationships between variables measured over multiple time points; many of the previous studies have used variants of this model. However, in cases where the measured constructs show stability within individual – as is clearly the case for language-related measures – these models are misspecified, since they assume that the only source of consistency between individuals is temporal autocorrelation (Hamaker, Kuiper, and Grasman 2015). To address this issue, Hamaker, Kuiper, and Grasman (2015) propose the random intercepts CLPM (RI-CLPM), which adds a latent intercept that accounts for individual variation across observation timepoints (shown in Figure 13.10). This is the approach used by Brinchmann, Braeken, and Lyster (2018), and they find significantly better fits for the RI-CLPM on their vocabulary/grammar data than the standard CLPM. Hence, we use this model in our analyses below.
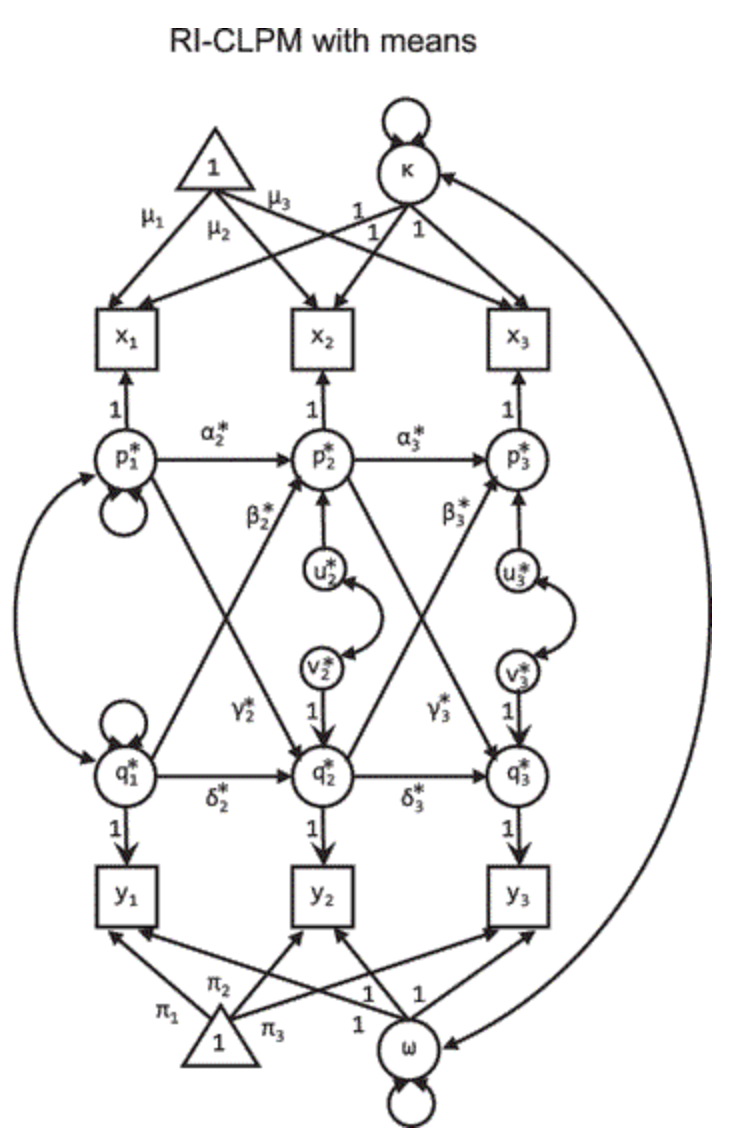
Figure 13.10: The random intercept cross-lagged panel model. Figure reproduced from Hamaker, Kuiper, and Grasman (2015). Circles represent observed variables, squares represent latent variables, and directed edges represent regression effects.
We include data from two different longitudinal datasets. The first is a group of children from a study conducted by Virginia Marchman with English-speaking children in Dallas, TX (N = 247). This dataset includes children with three waves of data collection centered around 18, 24, and 30 months; we included children if they contributed to two waves (N = 160) or all three waves (N = 83), for a total of 243 children. The offsets between waves varied somewhat in these data, but for simplicity, we split all administrations into three time points: 18–21 months, 22–25 months, and 26–30 months.
The second dataset is a large group of longitudinal administrations in the Norwegian normative data, including a total of 1,565 children. These children’s parents were invited to complete multiple CDIs online every month or few months, with many parents completing two and a small number completing 10 or more. For purposes of discrete analysis, we binned these continuous data into two-month waves from 18–35 months (the small number of 36-month-olds were included in the oldest wave). We then included children with two or more administrations, each falling in a different wave (N = 1141). Table 13.1 shows the distribution of how many observations are available for children across different waves.
| Number of observations | Number of children |
|---|---|
| 2 | 794 |
| 3 | 134 |
| 4 | 67 |
| 5 | 72 |
| 6 | 43 |
| 7 | 15 |
| 8 | 13 |
| 9 | 3 |
Using these two datasets, we fit RI-CLPM models.26 These models measure the magnitude of the reciprocal relationships between grammar and vocabulary over time. Coefficient weights on the paths between latent grammar and vocabulary are then interpretable as temporal influences. Following the RI-CLPM specification in Hamaker, Kuiper, and Grasman (2015), we posited latent variables \(\kappa\) and \(\omega\) that describe stability in vocabulary and grammar, respectively.
Figure 13.11 shows the fitted model for the English data. Coefficient estimates from vocabulary to grammar are large and significant (\(\beta_{p1-c2}\) = 0.95, p < 0.001, \(\beta_{p2-c3}\) = 0.77, p < 0.001). These are consistently higher than estimates from grammar to vocabulary (which are both small and non-significant).
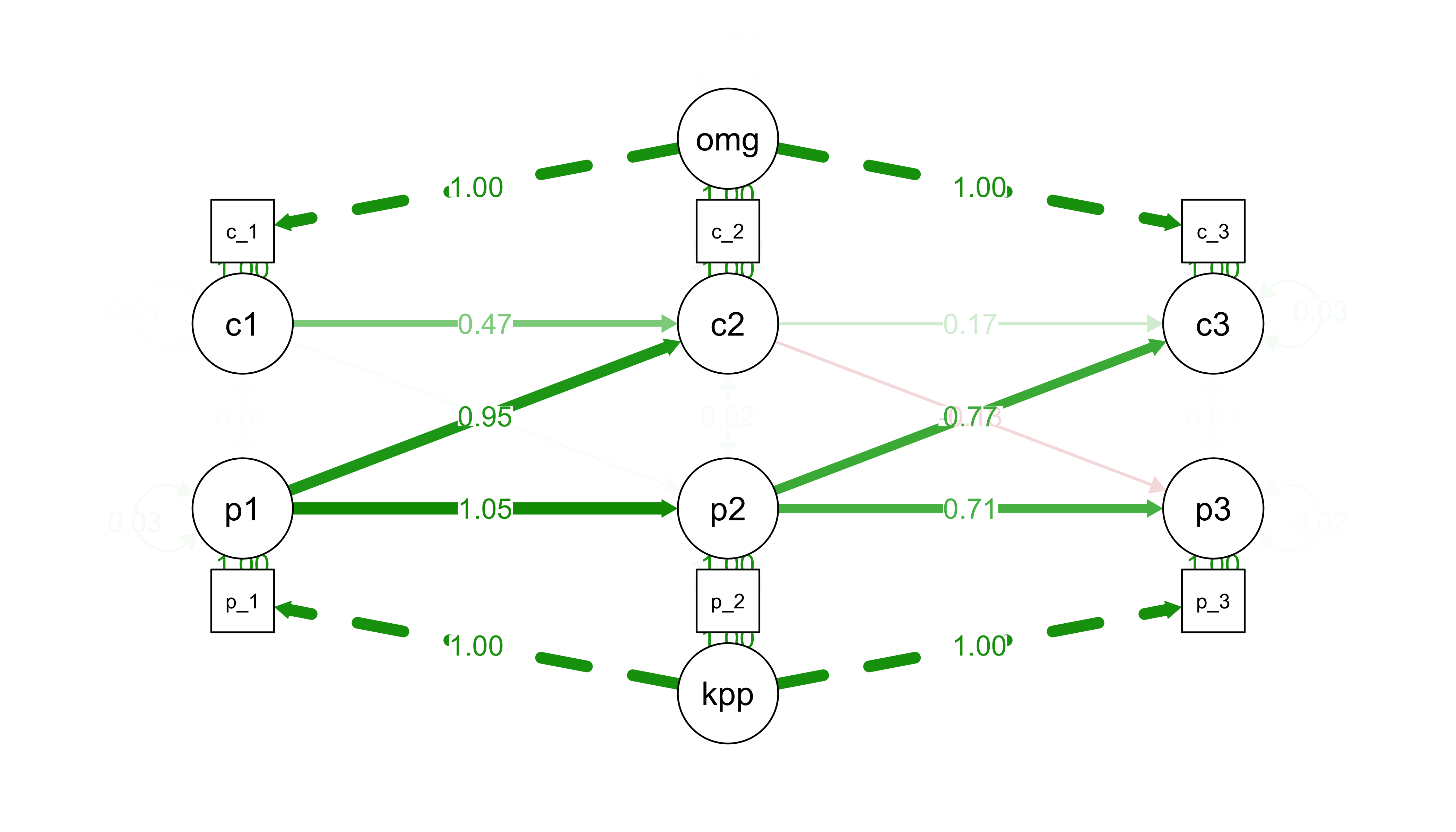
Figure 13.11: RI-CLPM model fit to English (American) data. Path diagram for latent (circles) and observed (squares) variables. Edges show estimated regression coefficients, scaled and colored by estimate magnitudes. Uppercase P variables indicate production coefficients, while C variables indicate grammatical complexity coefficients. Lowercase square variables are observed data. kpp and omg denote global intercepts.
Figure 13.12 shows the analogous fitted model for the Norwegian data.27 Coefficient estimates from vocabulary to grammar are large; as in the English data, these are consistently higher than estimates from grammar to vocabulary (which are both small and non-significant). Coefficient estimates are shown in Table 13.2.
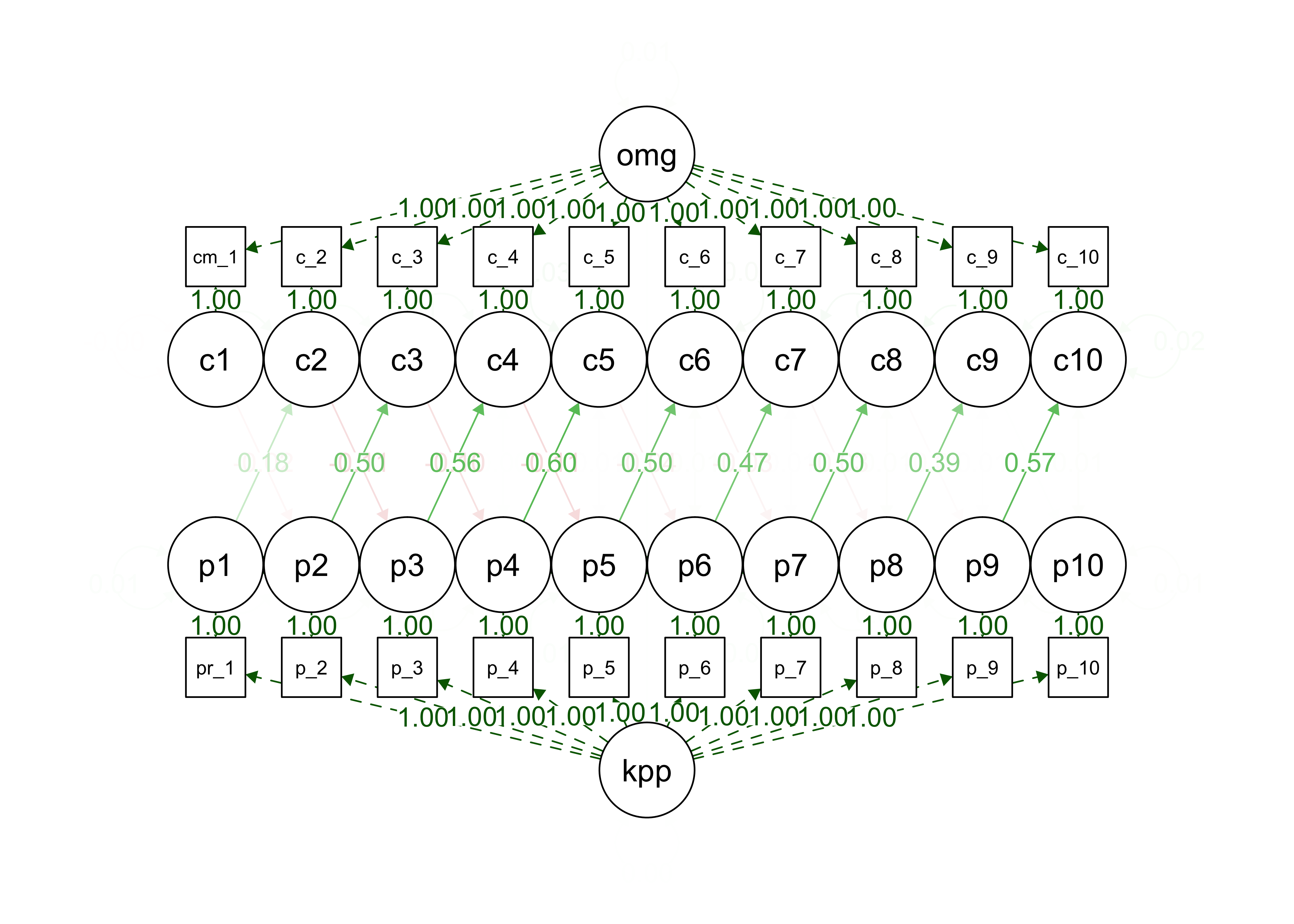
Figure 13.12: RI-CLPM model fit to Norwegian data. Plotting conventions are as above; P indicates production, while C indicates complexity.
| Predicted | Predictor | \(\beta\) | SE | p |
|---|---|---|---|---|
| p10 | c9 | 0.004 | 0.057 | 0.943 |
| p9 | c8 | –0.010 | 0.037 | 0.795 |
| p8 | c7 | –0.028 | 0.041 | 0.489 |
| p7 | c6 | –0.035 | 0.040 | 0.388 |
| p6 | c5 | –0.044 | 0.041 | 0.283 |
| p5 | c4 | –0.113 | 0.058 | 0.050 |
| p4 | c3 | –0.095 | 0.059 | 0.107 |
| p3 | c2 | –0.107 | 0.093 | 0.248 |
| p2 | c1 | –0.022 | 0.178 | 0.900 |
| c10 | p9 | 0.568 | 0.140 | < 0.001 |
| c9 | p8 | 0.393 | 0.099 | < 0.001 |
| c8 | p7 | 0.502 | 0.085 | < 0.001 |
| c7 | p6 | 0.469 | 0.078 | < 0.001 |
| c6 | p5 | 0.495 | 0.060 | < 0.001 |
| c5 | p4 | 0.600 | 0.067 | < 0.001 |
| c4 | p3 | 0.563 | 0.060 | < 0.001 |
| c3 | p2 | 0.496 | 0.090 | < 0.001 |
| c2 | p1 | 0.181 | 0.205 | 0.377 |
In both of these cases, we see strong evidence for cross-lagged influences of vocabulary on grammar, but not grammar on vocabulary. These results are consistent with the idea that, early in acquisition, learning vocabulary items provides the materials for generalization of grammatical constructions and rules – following the general line of speculation in Bates et al. (1994). In contrast, our findings are prima facie less consistent with results that show smaller relationships (Hoff, Quinn, and Giguere 2017) or grammar-to-vocabulary linkages (Brinchmann, Braeken, and Lyster 2018), both in older children. But in fact, we might expect a reversal in directionality for these relationships over time. Early in development, some vocabulary is necessary to get grammar learning off the ground. But later on, as grammatical rules stabilize (probably after age 3), grammar then serves to help elucidate the meanings of complex sentences, allowing syntactic bootstrapping of new word meanings (Gleitman 1990).
13.5 Discussion
In this chapter, we revisited classic findings on the relationship between grammar and the lexicon and explored novel questions regarding the role of age in this relation. Our results provide general support for a constructivist view, in that, in these 12 languages, variance in vocabulary production strongly aligns with variance in grammar. However, we also estimated additional age-related contributions, specifically contrasting the links to morphological forms vs. syntactic constructions. In general, we find that measures of grammar that are more closely aligned with syntax are modulated by age to a greater extent than those reflecting inflectional morphology.
As with the correlations reported in Chapter 7, parent bias is a potential confound for these correlational analyses. If some parents tend to over-report on their child’s language more than others do – for reasons such as sensitivity, optimism, greater time spent with the child – then this over-reporting would likely extend across linguistic domains. Thus, in principle an observed correlation between two sections of a single parent report form could be driven by parent bias acting independently on each section without any connection.
Two studies provide evidence against this deflationary hypothesis. First, Moyle et al. (2007) used a combination of parent report and standardized assessments (e.g., the Preschool Language Scale) to provide evidence for the same relation in both typically-developing and late-talking children from 2 to 5 years of age. Second, Brinchmann, Braeken, and Lyster (2018) give a similar analysis using cross-lagged structural equation models. Critically, their work relied only on direct testing of the child (not parent report) using standardized instruments. In their model, they found a strong correlation between the time-invariant (trait-like) components of vocabulary and grammar (r = 0.72). While this correlation is somewhat smaller than the correlations we report here, it is still quite large – and it appears in a model that also controls for a number of other relationships.
Intriguingly, however, the Brinchmann, Braeken, and Lyster (2018) study suggests that as grammar-lexicon correlations are cross-lagged, grammar to vocabulary links are stronger than vocabulary to grammar links, although neither could be characterized as strong. We followed up on this finding by fitting similar models to our own data, showing the opposite result (stronger vocabulary to grammar links across two languages). One potential reconciliation of these two findings is that early in development, more vocabulary allows for more generalization, but then later, syntactic bootstrapping effects are more important. Regardless, combined with the Moyle et al. (2007) study, these findings suggest that reporting bias is very likely not the sole cause of the correlations we observed.
Our analyses go beyond earlier work by also investigating the relationship of age to vocabulary and grammar. One possibility is that age-related developments are dependent on maturational factors that operate on grammatical development in a domain-specific way, independent of lexical-semantic processes. Another possibility is that age-related effects are a reflection of domain-general learning mechanisms, such as attention or working memory, that provide differential support for sentence-level processes than word-internal ones (Gathercole et al. 2013). Yet another possibility is that by an older age, children have received more linguistic input from which to generalize grammatical structure. Future studies should also explore the extent to which lexical and age-related processes are shaped, either independently or in tandem, by features of the learning environments that children experience (e.g., Weisleder and Fernald 2013; Hoff, Quinn, and Giguere 2017; Brinchmann, Braeken, and Lyster 2018).
In sum, questions about the nature of morphosyntactic representations in early language have often seemed deadlocked. By mapping out developmental change across large samples and multiple languages, our findings challenge theories from across the full range of perspectives to more fully describe the mechanistic factors underlying the interaction of vocabulary, grammar, and development.
At the risk of some circularity, we note that given the high degree of correlation with vocabulary (shown below), grammatical complexity items should inherit some presupposition of reliability and validity.↩︎
It appears possible that the Québécois French data have some issue for this item, given the very flat slope we observed. We speculate that this could perhaps be due to misinterpretation of the way the item is worded.↩︎
We gratefully acknowledge code from jflournoy.github.io/2017/10/20/riclpm-lavaan-demo.↩︎
Because of the high degree of missingness in this dataset, fititng these models was difficult and so we interpret standard errors with some caution.↩︎